- 필요성
- 끊임없이 생성되는 ‘실시간 정보’ 를 다양한 종류의 수신자에게 ‘빠르고 신뢰성’ 있게 전달할 수 있는 수단이 필요하다.
- 대부분 정보 생산자 어플리케이션 과 소비자 어플리케이션은 분리되어 있고, 서로 접근이 불가능 하다.
- 빅테이터 시대의 과제
- 거대한 데이터를 수집하기
- 수집한 데이터를 분석하기
- 분석의 대상
- 사용자 행위 데이터
- 애플리케이션 성능 모니터링 데이터
- 활동 로그 데이터
- 이벤트 메시지
- 메시지 퍼블리싱
- 다양한 애플리케이션의 메시지를 서로 전달 할 수 있도록 연결하는 구조를 말한다.
- 분석의 대상
- 카프카
- 실시간으로 대량의 정보를 다루고 여러 정보 소비자에게 빠르게 전달하는 과정에서 생기는 문제점을 해결한 솔루션 이다.
- 카프카의 특징
- 비 휘발성 : 정보의 유실이 없음, 아파치 카프카는 O(1) 디스크 구조로 디자인 되어서 아무리 많은 양의 저장 메시지라도 상수 시간 성능을 제공한다.
- 높은 처리량 : 일반 상용 하드웨어 에서 초당 수백만건의 메시지를 처리할 수 있게 설계 되었다.
- 분산 : 명시적으로 카프카 서버들을 대상으로 메시지 ‘파티셔닝’ 을 지원한다. 또한, 소비자들이 속한 클러스터 단위로 분산 소비를 지원하는데 파티션 단위로만 순서를 갖는다.
- 실시간 : 생산자 스레드에 의해 생성된 메시지들은 즉시 소비자 스레드에서 볼 수 있어야 한다. 이 특징은 복합 이벤트 처리 기반 시스템의 필수 특성이다.
- 카프카 메시징 시스템을 이용한 빅데이터 집계-분석 시나리오
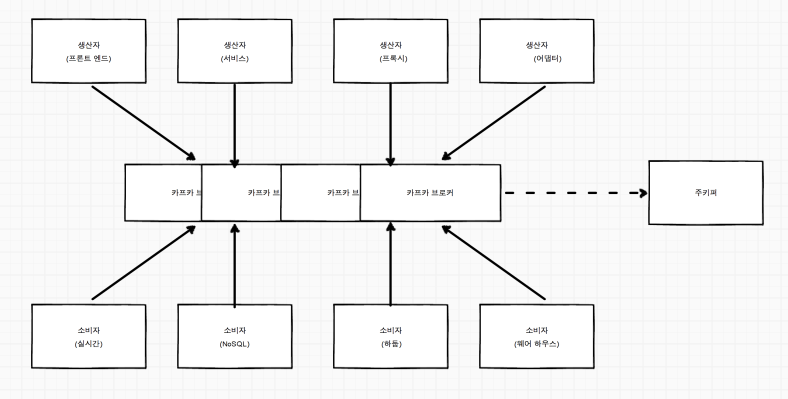
- 카프카의 필요성
- 로그인, 페이지 방문, 클릭, 소셜네트워킹 활동과 같은 사용자 활동 이벤트, 운영 시스템 정보 와 같은 데이터 대량의 데이터를 ‘실시간’ 분석에 활용할 수 있다.
- 아파치 카프카는 활동 스트림 데이터를 처리하는데 유용하다는 관점에서 Scribe, Flume 과 유사해 보이지만, 아키텍쳐 관점에서 ActiveMQ, RabbitMQ 와 같은 메시징 시스템에 좀 더 가깝다.
- 카프카는 하둡 시스템으로의 병렬로드와 클러스터의 장비들에 의한 실시간 분할 소비를 지원해서 오프라인과 온라인 처리를 통합하는 것을 목적으로 한다.
Category kafka
Kafka 학습에 들어가며…
역사
아파치 카프카는 2011년 링크드인 이 자사에서 웹사이트가 생성하는 다양한 소스로부터 나오는 대량의 이벤트를 처리하기 위해 만들어졌다.
아파치 카프카는 2011년 6월 아파치 인큐베이터 프로젝트에 등록되었고, 1년 만인 2012년 10월에 아파치 인큐베이터를 졸업하고, Top 프로젝트로 승격 되었다.
아파치 카프카는 저지연성을 가지지만, throughput 에 주안점을 두지 않은 ActiveMQ 와 다양한 소비자를 다룰 때, 지연시간 을 보장하지 못 하는 Flume, Scribe 두 솔루션 간의 큰 차이를 메우기 위해 만들어졌다.
하둡 같은 대용량 배치 처리 시스템과 스트리밍 처리를 하는 스톰에 데이터를 전달하는 중간자 역할을 할 수 있다.
